개요 #
Apache Spark는 대규모 분산 데이터 처리를 위한 통합 분석 엔진입니다. 기존 Hadoop MapReduce의 한계를 극복하고, 메모리 기반 처리를 통해 획기적인 성능 향상을 제공하는 현대적인 빅데이터 처리 플랫폼입니다.
Apache Spark의 핵심 특징 #
Spark’s design philosophy centers around four key characteristics
- Speed
- Ease of use
- Modularity
- Extensibility
1. 뛰어난 성능 (Speed) #
- 메모리 기반 처리: 중간 결과를 메모리에 저장하여 Hadoop MapReduce 대비 10-100배 빠른 처리 속도
- DAG 최적화: 방향성 비순환 그래프(Directed Acyclic Graph)를 통한 효율적인 작업 스케줄링
- Tungsten 엔진: 전체 단계 코드 생성으로 최적화된 바이트코드 실행
- 하드웨어 최적화: 멀티코어 CPU와 대용량 메모리를 효율적으로 활용
2. 개발 편의성 (Ease of Use) #
- 통합 API: 하나의 API로 배치, 스트리밍, 머신러닝, 그래프 처리 가능
- 다양한 언어 지원: Scala, Java, Python, SQL, R 지원
- 고수준 추상화: DataFrame과 Dataset을 통한 직관적인 데이터 조작
- 대화형 개발: Spark Shell을 통한 실시간 데이터 탐색
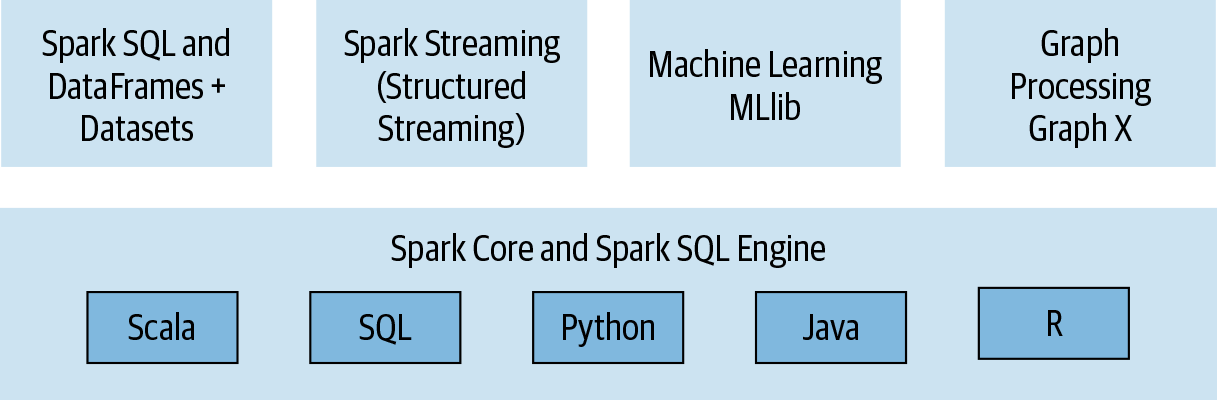
3. 모듈형 구조 (Modularity) #
- Spark는 다음과 같은 핵심 모듈들로 구성됨
Spark SQL - RDBMS 테이블이나 CSV, 텍스트, JSON 등의 구조화된 데이터 파일 형식에서 데이터를 읽고 Spark에서 영구 또는 임시 테이블을 구축할 수 있음.
- Java, Python, Scala, R의 Spark Structured API를 사용할 때 SQL 유사 쿼리를 결합해 Spark DataFrame에 읽힌 데이터를 쿼리할 수 있음
// In Scala
// Read data off Amazon S3 bucket into a Spark DataFrame
spark.read.json("s3://apache_spark/data/committers.json")
.createOrReplaceTempView("committers")
// Issue a SQL query and return the result as a Spark DataFrame
val results = spark.sql("""SELECT name, org, module, release, num_commits
FROM committers WHERE module = 'mllib' AND num_commits > 10
ORDER BY num_commits DESC""")
Spark MLLib
- MLLib은 DataFrame 기반 고수준 API를 기반으로 구축된 ML 알고리즘 제공
- Feature를 추출하거나 변환하고, 모델 학습 및 평가를 위한 파이프라인 구축하며, 배포를 위해 모델을 저장하고 다시 로드할 수 있음.
# In Python
from pyspark.ml.classification import LogisticRegression
...
training = spark.read.csv("s3://...")
test = spark.read.csv("s3://...")
# Load training data
lr = LogisticRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
송
# Fit the model
lrModel = lr.fit(training)
# Predict
lrModel.transform(test)
...
Structured Streaming
- Structured Streaming 모델의 가반에는 Spark SQL 코어 엔진이 있어 fault tolerance와 late-data semantics를 모두 처리함
- 아래 코드는 localhost 소켓에서 읽고 Kafka 토픽에 단어 수 결과를 전송
# In Python
# Read a stream from a local host
from pyspark.sql.functions import explode, split
lines = (spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())
# Perform transformation
# Split the lines into words
words = lines.select(explode(split(lines.value, " ")).alias("word"))
# Generate running word count
word_counts = words.groupBy("word").count()
# Write out to the stream to Kafka
query = (word_counts
.writeStream
.format("kafka")
.option("topic", "output"))
GraphX
// In Scala
val graph = Graph(vertices, edges)
messages = spark.textFile("hdfs://...")
val graph2 = graph.joinVertices(messages) {
(id, vertex, msg) => ...
}
4. 확장성 (Extensibility) #
- 다양한 데이터 소스: HDFS, S3, Cassandra, HBase, MongoDB 등 지원
- 클러스터 매니저: YARN, Kubernetes, Mesos, Standalone 모드 지원
- 커넥터 생태계: 풍부한 서드파티 커넥터와 패키지
Spark 아키텍쳐 이해 #
핵심 구성 요소 #
- 클러스터 매니저(Cluster Manager)
- 드라이버(Driver)
- 실행기(Executor)
- 세션 (Session)
- Job
- Stage
- task
1. Spark Driver #
- SparkSession 생성 및 관리
- 작업을 DAG로 변환하고 스케줄링
- 클러스터 매니저와 리소스 협상
- Executor와 직접 통신
2. SparkSession #
- SparkSession은 Spark의 모든 기능에 대한 단일 통합 진입점
// In Scala
import org.apache.spark.sql.SparkSession
// Build SparkSession
val spark = SparkSession
.builder
.appName("LearnSpark")
.config("spark.sql.shuffle.partitions", 6)
.getOrCreate()
...
// Use the session to read JSON
val people = spark.read.json("...")
...
// Use the session to issue a SQL query
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM table_name")
3. Cluster Manager #
- Standalone: Spark 내장 클러스터 매니저
- YARN: Hadoop 생태계와의 통합
- Kubernetes: 컨테이너 기반 배포
- Mesos: 범용 클러스터 매니저
4. Spark Executor #
- 실제 작업 실행
- 데이터 캐싱 및 저장
- Driver와 양방향 통신
5. Job #
- 스파크 액션(e.g.
save(), collect())에 대한 응답으로 생성되는 여러 task로 이루어진 병렬 연산
6. Stage #
- 스파크의 각 Job은 Stage라고 불리는 서로 의존성을 갖는 다수의 task 모음으로 나뉨
7. Task #
- 스파크 각 Job별 Executor로 보내지는 작업 할당의 가장 기본적인 단위
- 개별 task slot에 할당되고, 데이터의 개별 Partition을 갖고 작
배포 모드 #
| 모드 | Driver 위치 | Executor 위치 | 특징 |
|---|---|---|---|
| Local | 로컬 JVM | 로컬 JVM | 개발/테스트용 |
| Standalone | 클러스터 노드 | 클러스터 노드 | 간단한 배포 |
| YARN Client | 클라이언트 | YARN 컨테이너 | 대화형 작업 |
| YARN Cluster | YARN 컨테이너 | YARN 컨테이너 | 프로덕션 배치 |
| Kubernetes | K8s Pod | K8s Pod | 클라우드 네이티브 |